写在前面 参加这个比赛其实主要目的是赚钱(感谢周师姐的校友基金,最后含泪收下 7000¥ ),所以以下很多内容可能并不专业。
最终的结果是全国第 40 名,进决赛一共有 50 个队伍,不过由于加权压力(目前估计加权相较于大二上要掉 6 分左右),决赛不一定会付出太多心血去打了。
感谢我的队友 Sazikk 和我一起熬夜肝代码,并且忍耐我的屎山代码长达 21 天之久。由于屎山太多了,所以出现屎的部分会标注。
Sazikk 个人博客:https://sazikk.github.io 目前已有数十万的观看量(狗头https://github.com/SaZiKK/miniob-2024 https://ustb-806.github.io/blogs/2024/11/oceanbase/
个人心得 参加这个比赛需要什么能力:
较强的 C++ 开发能力
一定的 SQL 语言理解能力
对 miniob 内核有较好的理解
miniob 框架解析 我负责的题目 drop table
题目要求删除某个表格,一个表格的信息包括三种:数据信息 + 索引信息 + 表格元数据
数据信息:真实存放到表格当中的数据
索引信息:一个索引对应一棵 B+ 树
表格元数据:各种表格的描述信息
drop table 不需要算子,需要执行器
前端 lex yacc 完善 lex 加入关键字 DROP
1 DROP RETURN_TOKEN (DROP) ;
yacc 加入语句
1 2 3 4 5 6 drop_table_stmt:new ParsedSqlNode (SCF_DROP_TABLE);3 ;free ($3 );
STMT 设计 删除表格只需要表格的表名,当然正常来说在 STMT 级就应该通过表格名称获取到实际的 Table 了,但是当时写的时候放到了 Db 的删除表格函数中。
EXECUTE 设计 在执行器中通过调用 db 的删除表格函数或者 table 的自毁函数。表格的自毁函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 RC Table::drop () {table_data_file (base_dir_.c_str (), table_meta_.name ());unlink (data_file.c_str ());int indexNum = table_meta_.index_num ();for (int i = 0 ; i < indexNum; i++) {auto *index_meta = table_meta_.index (i);table_index_file (base_dir_.c_str (), table_meta_.name (), index_meta->name ());unlink (index_file.c_str ());table_meta_file (base_dir_.c_str (), table_meta_.name ());unlink (meta_file.c_str ());return RC::SUCCESS;
update
虽然题目只要求单字段的更新,但是由于后面很快就要扩充,所以下面直接放完整版。
需要注意的有两点,如何将 在某些字段修改为某值 推得 在内存某些位置修改二进制数据;以及对于多个字段的更新,必须同时成功或失败,也即先判断后修改(或回滚),不仅有单个字段间的回滚,还有单个元组间的回滚。
update 语句不需要执行器,需要算子
前端 lex yacc 完善 lex 加入关键字 UPDATE
1 UPDATE RETURN_TOKEN (UPDATE) ;
yacc 加入语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 update_stmt: new ParsedSqlNode (SCF_UPDATE);2 ;if ($6 != nullptr ) {swap (*$6 );delete $6 ;if ($5 != nullptr )swap (*$5 );emplace_back (*$4 );reverse ($$->update.update_targets.begin (), $$->update.update_targets.end ());
对于 ParseSqlNode,新增 update 语句对应的 node。
1 2 3 4 5 6 7 8 9 10 11 12 struct UpdateSqlNode {struct UpdateTarget {bool is_value;
STMT 设计 update 语句对应的 STMT 中包含:所有修改域信息(FieldMeta),目标表格,筛选对应的 STMT(FilterStmt),以及处理好的 UpdateTarget 数组。
第一步,拿到表格
第二步,通过所有修改域的名称,拿到全部修改域,注意顺序是不重要的,因为它们都是同时成功或同时失败的。
第三步,如果有子查询需要将子查询转化为一个 Value,后面对应的题再解释。
逻辑算子和物理算子设计 逻辑算子中需要包含表格以及一个数组,数组表示需要更新的域和值。
1 2 Table *table_ = nullptr ;
物理算子直接继承逻辑算子中的表格和<域, 值>数组,除此之外还需要包含一个 Record 数组,因为我们要处理单个元组的回滚。在存在 unique index 的情境下,一条 update 语句可能对多个元组进行修改,
例如:
id
num
col
id1
num1
col1
id2
num2
col2
id3
num3
col3
update 语句需要修改第一个元组和第三个元组的 id, col 字段。
元组级别的回滚:更新第一个元组没问题,但是更新第三个元组是非法的。
字段级别的回滚:更新某个元组时,更新 id 域没问题,但是更新 col 域是非法的。
1 2 3 4 Table *table_ = nullptr ;nullptr ;
物理算子 open 函数设计:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 RC UpdatePhysicalOperator::open (Trx *trx, const Tuple *main_tuple) {if (children_.empty ()) {return RC::SUCCESS;0 ];open (trx, main_tuple);if (rc != RC::SUCCESS) {LOG_WARN ("failed to open child operator: %s" , strrc (rc));return rc;while (OB_SUCC (rc = child->next (main_tuple))) {current_tuple ();if (nullptr == tuple) {return rc;static_cast <RowTuple *>(tuple);record ();emplace_back (std::move (record));close ();if (records_.empty ()) {LOG_WARN ("no records to update" );char *> backup_datas;for (Record &record : records_) {char *old_data = record.data ();char *backup_data = (char *)malloc (record.len ());memcpy (backup_data, old_data, record.len ());push_back (backup_data);size_t update_num = 0 ;for (Record &record : records_) {update_records (table_, record, update_map_);if (rc != RC::SUCCESS) {for (int i = 0 ; i < (int )update_num; ++i) {char *backup_data = backup_datas[i];set_data (backup_data);record_handler ()->update_record (&record);return rc;return RC::SUCCESS;
update 算子一般没有上层算子,所以不需要 next 函数,open 函数中调用了子算子的 close 函数,所以也不需要 close 函数。但理论上子算子的 close 函数放到 update 算子的 close 函数中会更好。
expression
将万物都改成 expression 的过程 1.将谓词语句的 value/field op value/field 结构改成 expression op expression
之前提到过,在 select 语句中,会将查询的表达式进行绑定,例如将 UnboundField 绑定为 Field。在 Filter 部分,如果想要支持任何类型的 expression,也需要绑定的环节。miniob 初始的框架只包含了对 UnboundField 的绑定,
理论上,应该模仿 select 语句的绑定,使用 ExpressionBinder 类来完成绑定的行为,但当时写的过于潦草,采用了纯粹的 switch 来完成。例如在下面的代码中完成了对表达式 expr 的绑定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 RC FilterStmt::bind_filter_expr (Db *db, Table *default_table, std::unordered_map<std::string, Table *> *tables, unique_ptr<Expression> &expr, bool &use_flag, std::unordered_map<string, string> alias_map, std::unordered_map<string, Table *> table_map) if (expr == nullptr ) return RC::INVALID_ARGUMENT;switch (expr->type ()) {case ExprType::VALUE: {try_get_value (value);if (rc != RC::SUCCESS) return rc;if (value.attr_type () == AttrType::DATE && !DateType::check_date (&value)) return RC::INVALID_ARGUMENT;break ;case ExprType::VALUELIST: {get_value_list (value_list);if (rc != RC::SUCCESS) return rc;for (auto it : value_list)if (it.attr_type () == AttrType::DATE && !DateType::check_date (&it)) return RC::INVALID_ARGUMENT;break ;case ExprType::SUBQUERY: {return RC::SUCCESS;break ;case ExprType::UNBOUND_FIELD: {nullptr ;const FieldMeta *field = nullptr ;get_table_and_field (db, default_table, tables, expr.get (), table, field, use_flag, alias_map, table_map);if (rc != RC::SUCCESS) return rc;make_unique <FieldExpr>(table, field);break ;case ExprType::ARITHMETIC: {static_cast <ArithmeticExpr *>(expr.get ());if (arith_expr->left () != nullptr ) {bind_filter_expr (db, default_table, tables, arith_expr->left (), use_flag, alias_map, table_map);if (rc != RC::SUCCESS) return rc;if (arith_expr->right () != nullptr ) {bind_filter_expr (db, default_table, tables, arith_expr->right (), use_flag, alias_map, table_map);if (rc != RC::SUCCESS) return rc;break ;case ExprType::VECFUNC: {static_cast <VecFuncExpr *>(expr.get ());if (vec_func_expr->child_left () != nullptr ) {bind_filter_expr (db, default_table, tables, vec_func_expr->child_left (), use_flag, alias_map, table_map);if (rc != RC::SUCCESS) return rc;if (vec_func_expr->child_right () != nullptr ) {bind_filter_expr (db, default_table, tables, vec_func_expr->child_right (), use_flag, alias_map, table_map);if (rc != RC::SUCCESS) return rc;break ;case ExprType::UNBOUND_AGGREGATION: {auto unbound_aggregate_expr = static_cast <UnboundAggregateExpr *>(expr.get ());name ();const char *aggregate_name = unbound_aggregate_expr->aggregate_name ();type_from_string (aggregate_name, aggregate_type);if (rc != RC::SUCCESS) return rc;child ();if (child_expr == nullptr ) return RC::INVALID_ARGUMENT;if (child_expr->type () == ExprType::STAR && aggregate_type == AggregateExpr::Type::COUNT) {new ValueExpr (Value (1 ));reset (value_expr);else {bind_filter_expr (db, default_table, tables, child_expr, use_flag, alias_map, table_map);if (rc != RC::SUCCESS) return rc;make_unique <AggregateExpr>(aggregate_type, std::move (child_expr));set_name (name);break ;default :return RC::INVALID_ARGUMENT;break ;return RC::SUCCESS;
当然,FilterObj 也需要改成 expression,而不是之前的 field/value 模式。
1 2 3 4 5 struct FilterObj {void operator =(FilterObj &obj) { this ->expr = std::move (obj.expr); }void init (std::unique_ptr<Expression> expr) this ->expr = std::move (expr); }
在 yacc 中,也需要进行修改,condition 部分需要改成左右都为 expression。其中虽然我们将子查询也设计成了表达式,但是在解析的时候,子查询并不算为 expression,否则会出现冲突。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 expression comp_opnew ConditionSqlNode;false ;false ;2 ;1 ;new ValueExpr (Value (114514 ));new ConditionSqlNode;false ;true ;2 ;1 ;3 ;nullptr ;new ConditionSqlNode;true ;true ;2 ;1 ;nullptr ;3 ;nullptr ;new ConditionSqlNode;true ;false ;2 ;1 ;nullptr ;3 ;new ConditionSqlNode;false ;false ;2 ;1 ;3 ;new ConditionSqlNode;false ;true ;2 ;1 ;new ValueExpr (Value (114514 ));new ConditionSqlNode;false ;false ;2 ;1 ;5 ->push_back (*$4 );new ValueListExpr (*$5 );
在后面的日子中,我们将能改的都改成了 expression,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 enum class ExprType {
修改逻辑算子生成器 在逻辑算子的生成过程中,原始的 miniob 会将 Filter 中的 field/value 变成表达式,很明显现在这是多此一举,对此进行修改。
需要注意的是,当一个 STMT 创建算子之后,原来的全部 unique_ptr 都会被移动走,在子查询里,应该还会看到这句话。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 RC LogicalPlanGenerator::create_plan (FilterStmt *filter_stmt, unique_ptr<LogicalOperator> &logical_operator) {const std::vector<FilterUnit *> &filter_units = filter_stmt->filter_units ();for (FilterUnit *filter_unit : filter_units) {left ();right ();move (filter_obj_left.expr);move (filter_obj_right.expr);if (filter_unit->conjunction_type () == 1 )else if (filter_unit->conjunction_type () == 2 )bool need_value_cast = left->value_type () != AttrType::TUPLES && right->value_type () != AttrType::TUPLES && left->type () != ExprType::VALUELIST &&type () != ExprType::VALUELIST && filter_unit->comp () != CompOp::XXX_IS_NULL &&comp () != CompOp::XXX_IS_NOT_NULL;if (need_value_cast) {try_get_value (left_value);try_get_value (right_value);if (!left_value.get_null () && !right_value.get_null () && left->value_type () != right->value_type ()) {auto left_to_right_cost = implicit_cast_cost (left->value_type (), right->value_type ());auto right_to_left_cost = implicit_cast_cost (right->value_type (), left->value_type ());if (left_to_right_cost <= right_to_left_cost && left_to_right_cost != INT32_MAX) {type ();if (left->value_type () == AttrType::CHARS && right->value_type () == AttrType::INTS)make_unique <CastExpr>(std::move (left), AttrType::FLOATS);else make_unique <CastExpr>(std::move (left), right->value_type ());if (left_type == ExprType::VALUE) {if (OB_FAIL (rc = cast_expr->try_get_value (left_val))) {LOG_WARN ("failed to get value from left child" , strrc (rc));return rc;make_unique <ValueExpr>(left_val);else {move (cast_expr);else if (right_to_left_cost < left_to_right_cost && right_to_left_cost != INT32_MAX) {type ();if (left->value_type () == AttrType::INTS && right->value_type () == AttrType::CHARS)make_unique <CastExpr>(std::move (right), AttrType::FLOATS);else make_unique <CastExpr>(std::move (right), left->value_type ());if (right_type == ExprType::VALUE) {if (OB_FAIL (rc = cast_expr->try_get_value (right_val))) {LOG_WARN ("failed to get value from right child" , strrc (rc));return rc;make_unique <ValueExpr>(right_val);else {move (cast_expr);else if (filter_unit->comp () == CompOp::LIKE_XXX || filter_unit->comp () == CompOp::NOT_LIKE_XXX) {type ();make_unique <CastExpr>(std::move (right), AttrType::CHARS);if (right_type == ExprType::VALUE) {if (OB_FAIL (rc = cast_expr->try_get_value (right_val))) {LOG_WARN ("failed to get value from right child" , strrc (rc));return rc;make_unique <ValueExpr>(right_val);else {move (cast_expr);else {LOG_WARN ("unsupported cast from %s to %s" , attr_type_to_string (left->value_type ()), attr_type_to_string (right->value_type ()));return rc;new ComparisonExpr (filter_unit->comp (), std::move (left), std::move (right));emplace_back (cmp_expr);if (!cmp_exprs.empty ()) {unique_ptr<ConjunctionExpr> conjunction_expr (new ConjunctionExpr(conjunction_types, cmp_exprs)) ;unique_ptr <PredicateLogicalOperator>(new PredicateLogicalOperator (std::move (conjunction_expr)));move (predicate_oper);return rc;int LogicalPlanGenerator::implicit_cast_cost (AttrType from, AttrType to) if (from == to) {return 0 ;return DataType::type_instance (from)->cast_cost (to);
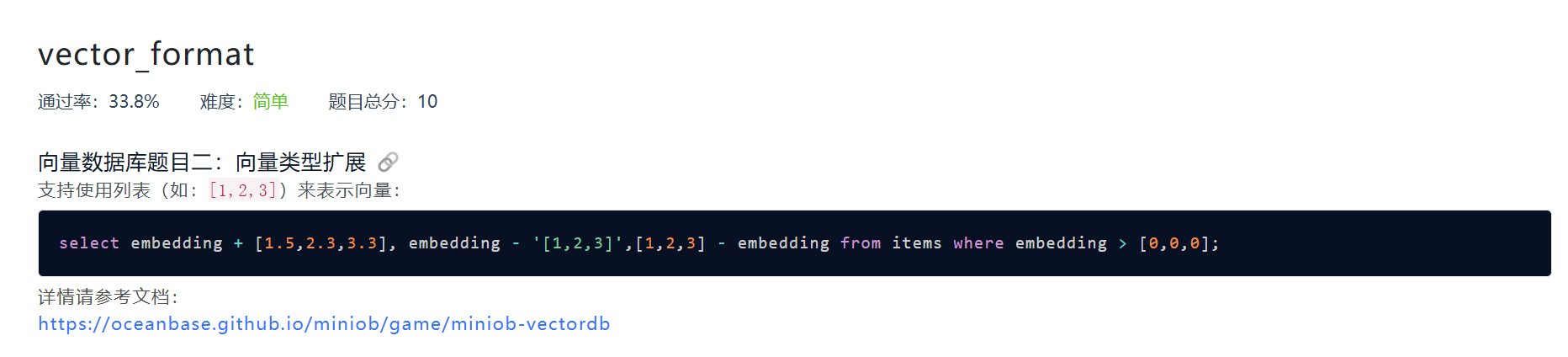
vector_basic
相对简单的一道题目,需要添加一种数据类型:VECTOR
我们采取的方式为,对于 ‘[1, 2, 3, 4]’ 这样的向量,先以字符串的形式输入进来,在 Value 的构造函数中进行格式检验,如果符合向量的格式,那么将其转化为向量存储,否则以字符串的方式存储。
有些边角的东西没有体现在下面的描述中,包括:插入向量时的长度不匹配问题 + 创建表格时的 VECTOR 长度检验等
Value 类的完善 首先,由于向量一定是 float 类型,所以实际的存储形式为 vector。Value 中有个字段 len,表示 Value 的长度,注意这个长度是占用空间的长度,对于 vector 来说,这个长度是 vector.size() * 4。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public :static bool isValidFormat (const char *input) static bool isValidNumber (const std::string &s) static RC string_to_vector (string str, vector<float > &result) void set_vector (std::vector<float > value_vector) vector<float > get_vector () const ;float get_vector_item (int idx) const int get_vector_size () const private :float > value_vector_;
isValidFormat, isValidNumber, string_to_vector 的设计如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 bool Value::isValidFormat (const char *input) if (input == nullptr || strlen (input) < 2 ) {return false ;if (input[0 ] != '[' || input[strlen (input) - 1 ] != ']' ) {return false ;std::string content (input + 1 , strlen(input) - 2 ) ;erase (std::remove (content.begin (), content.end (), ' ' ), content.end ());std::istringstream ss (content) ;while (std::getline (ss, token, ',' )) {if (!isValidNumber (token)) {return false ; return true ; bool Value::isValidNumber (const std::string &s) std::istringstream stream (s) ;float number;return stream.eof () && !stream.fail ();RC Value::string_to_vector (string str, vector<float > &result) {if (!Value::isValidFormat (str.c_str ())) return RC::INVALID_ARGUMENT;substr (1 , (int )str.size () - 2 );erase (std::remove (str.begin (), str.end (), ' ' ), str.end ());std::istringstream ss (str) ;while (std::getline (ss, token, ',' )) {push_back (FloatType::formatFloat(std::stof (token), 2 ));return RC::SUCCESS;
接下来是 Value 输入为字符串的构造函数,如果发现字符串的格式为数组形式,那么转化为 VECTOR。
1 2 3 4 5 6 7 8 Value::Value (const char *s, int len ) {float > value_vector;string_to_vector (s, value_vector);if (rc == RC::SUCCESS)set_vector (value_vector);else set_string (s, len);
接下来是 Value 和 data 的转换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 void Value::set_data (char *data, int length) switch (attr_type_) {case AttrType::CHARS: {set_string (data, length);break ;case AttrType::INTS: {int *)data;break ;case AttrType::FLOATS: {float *)data;break ;case AttrType::BOOLEANS: {int *)data != 0 ;break ;case AttrType::DATE: {int *)data;break ;case AttrType::VECTORS: {size_t element_size = sizeof (int );size_t num_elements = length / element_size;resize (num_elements);memcpy (value_vector_.data (), data, length);break ;case AttrType::TEXT: {set_text (data);break ;default : {LOG_WARN ("unknown data type: %d" , attr_type_);break ;const char *Value::data () const switch (attr_type_) {case AttrType::TEXT: {return value_.pointer_value_;break ;case AttrType::CHARS: {return value_.pointer_value_;break ;case AttrType::VECTORS: {return (const char *)(value_vector_.data ());default : {return (const char *)&value_;break ;
VECTOR 的各种运算 在 common/type 中,还需要完成有关 VECTOR 的各种计算、比较等。由于比较简单这里直接放上来了,不过需要注意的是,比赛要求向量的乘法是逐位相乘,也即两个向量的乘积仍为向量:[1, 2, 3] * [4, 5, 6] = [4, 10, 18]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 int VectorType::compare (const Value &left, const Value &right) const if (left.attr_type () != AttrType::VECTORS || right.attr_type () != AttrType::VECTORS || left.get_vector_size () != right.get_vector_size ())return INT32_MAX;int size = (int )left.get_vector_size ();int result = 0 ;for (int i = 0 ; i < size; i++) {if (left.get_vector ()[i] > right.get_vector ()[i]) {1 ;break ;else if (left.get_vector ()[i] < right.get_vector ()[i]) {-1 ;break ;return result;RC VectorType::add (const Value &left, const Value &right, Value &result) const {if (left.attr_type () != AttrType::VECTORS || right.attr_type () != AttrType::VECTORS || left.get_vector_size () != right.get_vector_size ())return RC::INVALID_ARGUMENT;int size = (int )left.get_vector_size ();vector<float > answer (size, 0 ) ;for (int i = 0 ; i < size; i++) answer[i] = left.get_vector ()[i] + right.get_vector ()[i];set_vector (answer);return RC::SUCCESS;RC VectorType::subtract (const Value &left, const Value &right, Value &result) const {if (left.attr_type () != AttrType::VECTORS || right.attr_type () != AttrType::VECTORS || left.get_vector_size () != right.get_vector_size ())return RC::INVALID_ARGUMENT;int size = (int )left.get_vector_size ();vector<float > answer (size, 0 ) ;for (int i = 0 ; i < size; i++) answer[i] = left.get_vector ()[i] - right.get_vector ()[i];set_vector (answer);return RC::SUCCESS;RC VectorType::multiply (const Value &left, const Value &right, Value &result) const {if (left.attr_type () != AttrType::VECTORS || right.attr_type () != AttrType::VECTORS || left.get_vector_size () != right.get_vector_size ())return RC::INVALID_ARGUMENT;int size = (int )left.get_vector_size ();vector<float > answer (size, 0 ) ;for (int i = 0 ; i < size; i++) answer[i] = left.get_vector ()[i] * right.get_vector ()[i];set_vector (answer);return RC::SUCCESS;RC VectorType::to_string (const Value &val, string &result) const {if (val.attr_type () != AttrType::VECTORS) return RC::INVALID_ARGUMENT;"[" ;for (auto it : val.get_vector ()) {2 );to_string (it);2 );erase (str.find_last_not_of ('0' ) + 1 , std::string::npos);if (str.back () == '.' ) {pop_back ();',' ;if ((int )result.length () > 1 ) result.pop_back ();"]" ;return RC::SUCCESS;
题目要求不仅要识别字符串类型的向量数据,还需要识别不带引号的向量数据。我在写的时候偷懒了,直接采取 [ + value + value_list + ],所以只需要在 yacc 中添加这一条规则即可。
lex 和 yacc 完善 lex 需要添加左右中括号的词语:
1 2 "[" RETURN_TOKEN (LBRACKET);"]" RETURN_TOKEN (RBRACKET);
yacc 需要添加对向量变量的识别:
1 2 3 4 5 6 7 8 9 10 11 12 value:float > nums;emplace_back ($2 ->get_float ());if ($3 != nullptr ) {reverse ($3 ->begin (), $3 ->end ());for (Value value : *$3 ) {emplace_back (value.get_float ());new Value (nums);
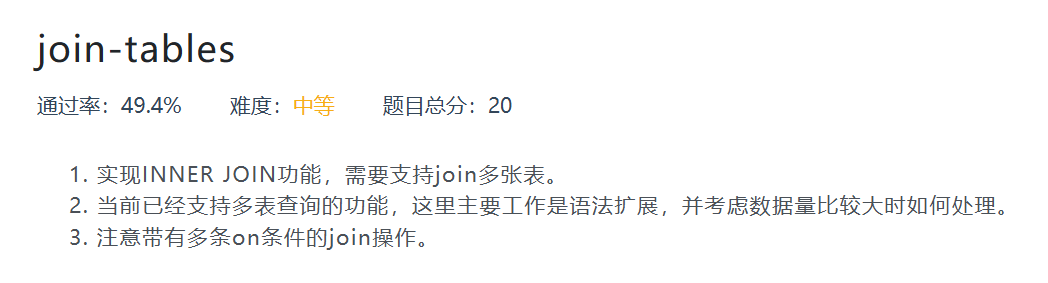
join-tables
join-tables 所涉及的算子在初始工程已经很完善了。简单来说,对于一条 select 语句可能有多个目标表格,其中第一个目标表格为主表格,后面的表格会跟主表格一并做笛卡尔积。创建算子的时候,第一个表格会创建 TableGet 相关算子,后面的表格会创建 JoinTable 相关算子。
对于 INNERJOIN,ON 中定义的谓词逻辑和 WHERE 中定义的谓词逻辑是完全平等的,所以,对于 ON 中的全部谓词逻辑,我们只需要将其视作 WHERE 中通过 AND 连结词连在一起的即可。
对于 join 部分,将其视作一个表达式,原因见 expression。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class JoinTableExpr : public Expression {public :JoinTableExpr (std::vector<ConditionSqlNode> conditions, unique_ptr<Expression> child) : conditions_ (conditions), child_ (std::move (child)) {}JoinTableExpr (std::vector<ConditionSqlNode> conditions, Expression *child) : conditions_ (conditions), child_ (child) {}virtual ~JoinTableExpr () = default ;ExprType type () const override { return ExprType::JOINTABLE; }AttrType value_type () const override { return AttrType::UNDEFINED; }RC get_value (const Tuple &tuple, Value &value) const override { return RC::INTERNAL; }const std::vector<ConditionSqlNode> conditions () const return conditions_; }const std::unique_ptr<Expression> &child () const return child_; }private :
lex 和 yacc 的完善 lex 需要完善对 JOIN/INNER JOIN/ON 的识别。
1 2 JOIN|INNER[ \t]+JOIN RETURN_TOKEN (INNER_JOIN) ;ON RETURN_TOKEN (ON) ;
对于 join 子句的部分,创建一个 expression 数组,数组的 expression 类型为 JoinTableExpr,每一个 JoinTableExpr 包含 join 的表格以及谓词逻辑语句。
select_stmt 也需要加入 join_list 部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 join_list:nullptr ;if ($5 != nullptr ) {5 ;else {new std::vector<std::unique_ptr<Expression>>;emplace_back (new JoinTableExpr (*$4 , $2 ));
select_stmt 的完善 在创建 SelectStmt 时,需要将 join 的表格和谓词语句添加到 select 语句中的表格列表和谓词语句列表中。谓词语句顺序无所谓,但是表格的顺序会影响输出表头的顺序,所以需要严格按照 JOIN 出现的顺序。
1 2 3 4 5 6 7 8 9 10 11 12 13 for (size_t i = 0 ; i < select_sql.join.size (); i++) {static_cast <JoinTableExpr *>(select_sql.join[i].get ());static_cast <UnboundTableExpr *>(join_table_expr->child ().get ());make_unique <UnboundTableExpr>(table_expr->table_name (), table_expr->table_alias ());emplace_back (move (temp));for (auto condition : join_table_expr->conditions ()) select_sql.conditions.emplace_back (condition);
null
题目要求支持一种特殊的数据类型:null,它不属于任何普通类型,却又能匹配任何普通类型。
整体来说,需要完成以下内容:
支持识别关键字 NULL IS NOT 等
支持创建表格时对特定域声明 NULL or NOT NULL = default
Value 类中添加对 NULL 的管理
支持插入数据时插入 NULL,并判断合法性
支持更新数据时更新 NULL,并判断合法性
支持谓词逻辑普通运算符对 NULL 计算,以及谓词逻辑新增运算 IS NULL and IS NOT NULL
额外需要考虑的一点为,Value 会被转换成 Record 写入内存,也即实际写入内存的是 01 串,而通过 01 串并不能知道这是什么类型。假设某个域类型为 INT,它可以通过表头信息知道:从该列拿出来的数据一定是 INT 类型,所以可以将 01 串按照 INT 的存储规则还原,但是对于 NULL 类型,由于其可以匹配任意类型,所以并不能通过某处记录的信息来得知拿出来的数据为 NULL 类型。
我们的处理是 bitmap 或者 写入特殊字符,使用 bitmap 会导致后面的并发 update 报错,至比赛结束仍不知道原因。不过 bitmap 无疑是最优美的解决方案。
—- WARING 下文有狗屎 —-
所以我们的处理方法是,对于一个 x 字节的数据,如果它的类型为 NULL,则向内存写入数据时,写入 x 字节的 ÿ,就是如此抽象。拿出数据时,首先检验 01 串是否为 x 字节的 ÿ 的 ASCII 码,
支持识别关键字 NULL IS NOT 等 lex 中需要添加新的词语解析
1 2 3 4 NULL RETURN_TOKEN (NULLABLE);[ \t] +NULL RETURN_TOKEN (UNNULLABLE);[ \t] +NULL RETURN_TOKEN (IS_NULL);[ \t] +NOT+[ \t] +NULL RETURN_TOKEN (IS_NOT_NULL);
支持创建表格时对特定域声明 NULL or NOT NULL = default yacc 中需要添加新的语法解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 new AttrInfoSqlNode;2 ;1 ;4 ;6 ;free ($1 );false ;true ;false ;
Value 类中添加对 NULL 的管理 Value 中添加标志位 is_null_,用于判断 Value 是否为 NULL。同时还需要维护各种构造函数,拷贝函数,运算符重载有关 NULL 的问题。同时 NULL 数据转化为 char * 写入内存的
支持插入数据时插入 NULL,并判断合法性 在将 Value 转化为 Record 时,需要额外做一步判断。如果插入的数据为 NULL 且该域不允许为 NULL,返回 FAILURE。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 RC Table::make_record (int value_num, const Value *values, Record &record) {if (value_num + table_meta_.sys_field_num () != table_meta_.field_num ()) {LOG_WARN ("Input values don't match the table's schema, table name:%s" , table_meta_.name ());return RC::SCHEMA_FIELD_MISSING;const int normal_field_start_index = table_meta_.sys_field_num ();int record_size = table_meta_.record_size ();char *record_data = (char *)malloc (record_size);memset (record_data, 0 , record_size);for (int i = 0 ; i < value_num && OB_SUCC (rc); i++) {const FieldMeta *field = table_meta_.field (i + normal_field_start_index);if (value.get_null ()) {if (field->can_be_null () == false ) {LOG_WARN ("failed to insert NULL to NOT_NULL field" );return RC::INVALID_ARGUMENT;set_value_to_record (record_data, value, field, i);else if (field->type () != value.attr_type ()) {cast_to (value, field->type (), real_value);if (OB_FAIL (rc)) {LOG_WARN ("failed to cast value. table name:%s,field name:%s,value:%s " , table_meta_.name (), field->name (), value.to_string ().c_str ());break ;set_value_to_record (record_data, real_value, field, i);else {set_value_to_record (record_data, value, field, i);if (OB_FAIL (rc)) {LOG_WARN ("failed to make record. table name:%s" , table_meta_.name ());free (record_data);return rc;set_data_owner (record_data, record_size);return RC::SUCCESS;
同时转换为 Record 时,也需要考虑 NULL 的情况。
1 2 3 4 if (value.get_null ()) {const char *flag = "ÿÿÿÿ" ;memcpy (record_data + field->offset (), flag, std::min (field->len (), 4 ));
支持更新数据时更新 NULL,并判断合法性 和插入数据区别不大,也是需要额外添加一层判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 RC Table::update_records (Record &record, std::vector<std::pair<Value, FieldMeta>> update_map_) {const int sys_field_num = table_meta_.sys_field_num ();const int user_field_num = table_meta_.field_num () - sys_field_num;nullptr ;for (auto it : update_map_) {for (int i = 0 ; i < user_field_num; i++) {const FieldMeta *field_meta = table_meta_.field (sys_field_num + i);const char *field_name = field_meta->name ();if (strcmp (field_name, it.second.name ()) == 0 ) {if (it.first.get_null ()) {if (field_meta->can_be_null () == false ) return RC::INVALID_ARGUMENT;else if (field_meta->type () != it.first.attr_type ()) {cast_to (it.first, field_meta->type (), real_value);if (OB_FAIL (rc)) return rc;break ;if (nullptr == targetFiled) {return RC::SCHEMA_FIELD_NOT_EXIST;char *old_data = record.data ();char *backup_data = (char *)malloc (record.len ());memcpy (backup_data, old_data, record.len ());for (auto it : update_map_) {update_record (record, it.second.name (), &it.first);if (rc != RC::SUCCESS) return rc;const char *> update_fields;for (auto &it : update_map_) {push_back (it.second.name ());this ->find_index_by_fields (update_fields);if (index != nullptr && update_fields.size () > 1 ) {insert_entry (record.data (), &record.rid ());if (rc != RC::SUCCESS && strcmp (old_data, backup_data) != 0 ) {LOG_ERROR ("Failed to update data, recovering. table=%s, rc=%d:%s" , name (), rc, strrc (rc));return rc;return RC::SUCCESS;RC Table::update_record (Record &record, const char *attr_name, Value *value) {const int sys_field_num = table_meta_.sys_field_num ();const int user_field_num = table_meta_.field_num () - sys_field_num;nullptr ;int i = 0 ;for (; i < user_field_num; i++) {const FieldMeta *field_meta = table_meta_.field (sys_field_num + i);const char *field_name = field_meta->name ();if (strcmp (field_name, attr_name) == 0 ) {if (value->get_null ()) {if (field_meta->can_be_null () == false ) return RC::INVALID_ARGUMENT;else if (field_meta->type () != value->attr_type ()) {cast_to (*value, field_meta->type (), real_value);if (OB_FAIL (rc)) return rc;move (real_value);break ;if (nullptr == targetFiled) {return RC::SCHEMA_FIELD_NOT_EXIST;int field_offset = targetFiled->offset ();int field_length = targetFiled->len ();char *old_data = record.data ();char *backup_data = (char *)malloc (record.len ());memcpy (backup_data, old_data, record.len ());if (value->length () > field_length && targetFiled->type () != AttrType::VECTORS) {memcpy (old_data + field_offset, value->data (), field_length);else {memcpy (old_data + field_offset, value->data (), value->length ());memset (old_data + field_offset + value->length (), 0 , field_length - value->length ());if (value->get_null ()) {const char *flag = "ÿÿÿÿ" ;memcpy (old_data + field_offset, flag, std::min (4 , field_length));set_data (old_data);this ->find_index_by_field (targetFiled->name ());if (index != nullptr ) {insert_entry (record.data (), &record.rid ());if (rc != RC::SUCCESS && strcmp (old_data, backup_data) != 0 ) {LOG_ERROR ("Failed to update data, recovering. table=%s, rc=%d:%s" , name (), rc, strrc (rc));return rc;update_record (&record);return RC::SUCCESS;
支持谓词逻辑普通运算符对 NULL 计算,以及谓词逻辑新增运算 IS NULL and IS NOT NULL 由于 Compare 部分我们写的比较复杂,这边只展示有关 IS NULL and IS NOT NULL 的函数,对于普通运算符,只需要在最上方判断:如果为 NULL,直接返回 false。不过需要注意,后面涉及到排序题目的时候,不能无脑返回 false,需要特殊考虑 NULL 和 NULL 的比较。
1 2 3 4 5 6 7 8 9 10 11 12 13 bool IS_NULL_Compare (CompType type_, const Value &left, const Value &right, const std::vector<Value> left_list, const std::vector<Value> right_list, const std::vector<std::vector<Value>> left_tuple_list, const std::vector<std::vector<Value>> right_tuple_list) if (type_ == CompType::VAL_LIST || type_ == CompType::VAL_VAL || type_ == CompType::VAL_TUPLES) {return left.get_null ();if (!left_list.empty () && type_ == CompType::LIST_VAL) {return left_list[0 ].get_null ();if (!left_tuple_list.empty () && type_ == CompType::TUPLES_VAL) {return left_tuple_list[0 ][0 ].get_null ();return false ;
update-select
本题要求 update 的更新目标值可以通过子查询得出,子查询第一版本是我的队友完成的,但是在写复杂子查询的时候将整个框架重构了一下。因为在看代码框架的时候发现,用于生成算子的部分是完全独立的,所以完全可以将生成算子的部分改成静态的,从而可以 : “随时随地,STNT -> 算子 -> 结果”。这样设计完之后,想要获取子查询的结果只需要一个 STMT,极大的简化了代码,甚至 update-select 并没有新增什么内容,只是在收集更新的 Value 时,多增一步,如果 Value 是子查询需要转化一下。
需要注意的是,准确说当时因为这个 debug 了好久,where 子句筛选出来的元组集合为空集时,即便子查询搜出来的结果不合法,也算 SUCCESS。
STMT -> vector< vector< Value>> 更近一步,设计一个函数,输入 STMT,输出为二维 Value 数组,省去中间的部分。函数设计如下:输入 STMT,输出 数据 + 表头信息。其中 main_tuple 为复杂子查询的内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 RC OptimizeStage::handle_sub_stmt (Stmt *stmt, std::vector<std::vector<Value>> &tuple_list, TupleSchema &tuple_schema, const Tuple *main_tuple) {static_cast <SelectStmt *>(stmt);tables ();for (auto it : tables) table_names += it->name ();if (!sub_expr_and_logical_oper.contains (table_names)) {create_logical_plan (stmt, logical_oper);if (rc != RC::SUCCESS && rc != RC::UNIMPLEMENTED) return rc;ASSERT (logical_oper, "logical operator is null" );insert (make_pair (table_names, std::move (logical_oper)));if (!sub_expr_and_physical_oper.contains (table_names)) {generate_physical_plan (sub_expr_and_logical_oper[table_names], physical_oper);if (rc != RC::SUCCESS) return rc;insert (make_pair (table_names, std::move (physical_oper)));get ();get_tuple_schema (physical_oper, tuple_schema);if (rc != RC::SUCCESS) return rc;get_tuple_list (physical_oper, tuple_list, main_tuple);return rc;RC OptimizeStage::create_logical_plan (Stmt *stmt, unique_ptr<LogicalOperator> &logical_operator) {if (nullptr == stmt) {return RC::UNIMPLEMENTED;return LogicalPlanGenerator::create (stmt, logical_operator);RC OptimizeStage::generate_physical_plan (unique_ptr<LogicalOperator> &logical_operator, unique_ptr<PhysicalOperator> &physical_operator) {create (*logical_operator, physical_operator);if (rc != RC::SUCCESS) {LOG_WARN ("failed to create physical operator. rc=%s" , strrc (rc));return rc;RC OptimizeStage::get_tuple_schema (PhysicalOperator *physical_operator, TupleSchema &tuple_schema) {return physical_operator->tuple_schema (tuple_schema);RC OptimizeStage::get_tuple_list (PhysicalOperator *physical_operator, std::vector<std::vector<Value>> &tuple_list, const Tuple *main_tuple) {open (nullptr , main_tuple);if (rc != RC::SUCCESS) {LOG_WARN ("failed to open sub physical operator. rc=%s" , strrc (rc));return rc;while (RC::SUCCESS == (rc = physical_operator->next (main_tuple))) {current_tuple ();for (int i = 0 ; i < tuple->cell_num (); i++) {cell_at (i, value);push_back (value);push_back (single_tuple);if (rc != RC::RECORD_EOF) return rc;close ();if (rc != RC::SUCCESS) return rc;return RC::SUCCESS;
update 中添加有关子查询的部分 如果发现有子查询,通过函数将其转化为二维 Value 数组,如果数组只有一个元素则合法,拿出来;如果数组为空,则等同于 NULL;如果数组不为空,等同一个非法的 Value,注意这里并没有直接返回 FAILURE,因为如果 where 子句筛选集为空集,即便子查询有误也返回 SUCCESS,所以这里通过特意构造非法 Value,如果 where 子句筛选集不为空集,则会识别非法 Value 并返回 FAILURE;如果 where 子句筛选集为空集,则不会有识别环节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 RC UpdateStmt::create (Db *db, UpdateSqlNode &update, Stmt *&stmt) {const char *table_name = update.relation_name.c_str ();find_table (table_name);if (table == nullptr ) {LOG_WARN ("no such table. db=%s, table_name=%s" , db->name (), table_name);return RC::SCHEMA_TABLE_NOT_EXIST;if (nullptr == db || nullptr == table_name) {LOG_WARN ("invalid argument. db=%p, table_name=%p" , db, table_name);return RC::INVALID_ARGUMENT;for (auto it : update.update_targets) {table_meta ().field (it.attribute_name.c_str ());if (nullptr == field_meta) {return RC::SCHEMA_FIELD_NOT_EXIST;push_back (*field_meta);insert (std::pair <std::string, Table *>(std::string (table_name), table));nullptr ;bool flag;create (db, table, &table_map, update.conditions.data (), static_cast <int >(update.conditions.size ()), filter_stmt, flag);if (rc != RC::SUCCESS) {LOG_WARN ("failed to create filter statement. rc=%d:%s" , rc, strrc (rc));return rc;for (int i = 0 ; i < (int )update.update_targets.size (); i++) {if (update.update_targets[i].is_value == false ) {create (db, update.update_targets[i].sub_select->selection, temp, flag);if (rc != RC::SUCCESS) return rc;reset ();handle_sub_stmt (temp, tuple_list, tuple_schema);if (rc != RC::SUCCESS) return RC::INVALID_ARGUMENT;if (tuple_list.empty ()) {set_null (true );else if (tuple_list.size () != 1 || tuple_list[0 ].size () != 1 ) {set_type (AttrType::UNDEFINED);else {0 ][0 ];true ;for (auto it : update.update_targets) {if (value.attr_type () == AttrType::DATE) {if (!DateType::check_date (value.get_date ())) {return RC::INVALID_ARGUMENT;else if (value.attr_type () == AttrType::CHARS) {if (value.get_string ().size () > BP_MAX_TEXT_SIZE) {return RC::INVALID_ARGUMENT;else if (value.attr_type () == AttrType::VECTORS) {if (value.get_vector_size () > BP_MAX_VECTOR_SIZE) {return RC::INVALID_ARGUMENT;new UpdateStmt (table, filter_stmt, field_metas, update.update_targets);return RC::SUCCESS;
alias
order-by
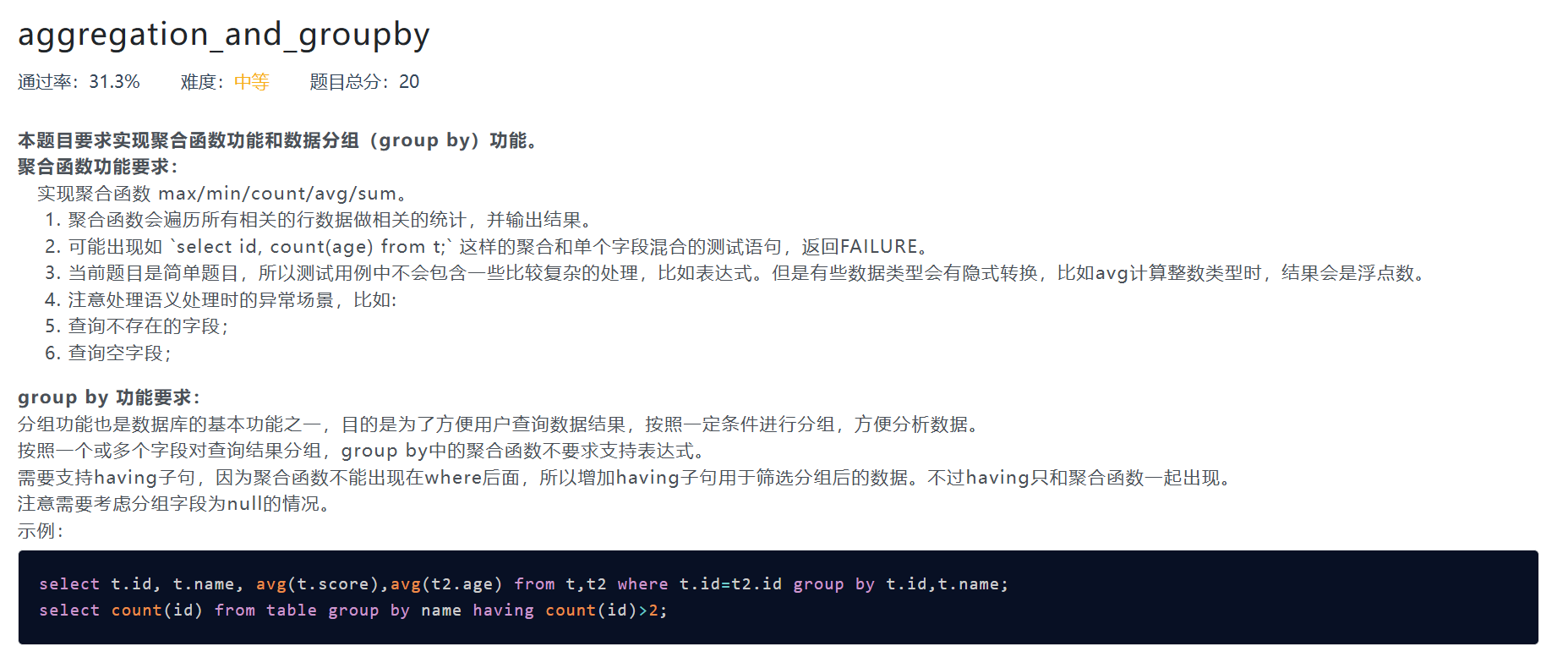
aggregation_and_groupby
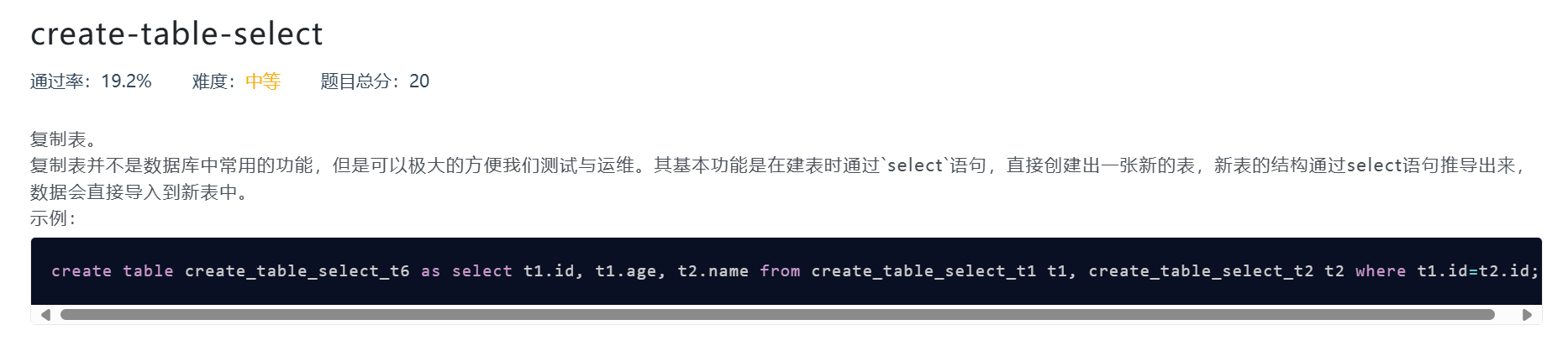
create-table-select
vector_rewrite
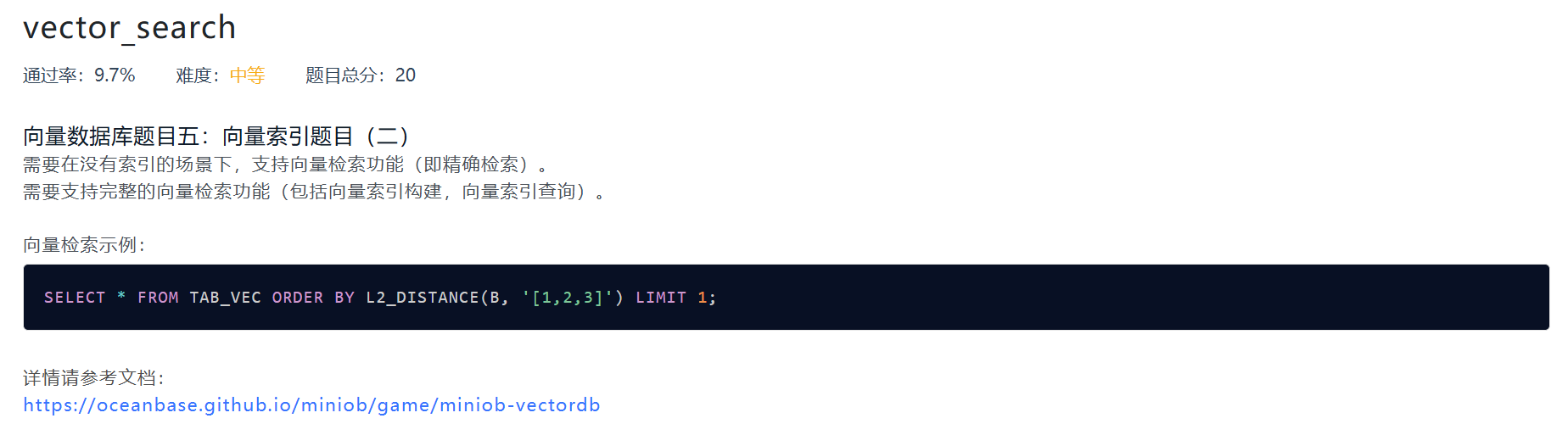
vector_search
complex-sub-query