downfall
downfall
Downfall attacks target a critical weakness found in billions of modern processors used in personal and cloud computers. This vulnerability, identified as CVE-2022-40982, enables a user to access and steal data from other users who share the same computer. For instance, a malicious app obtained from an app store could use the Downfall attack to steal sensitive information like passwords, encryption keys, and private data such as banking details, personal emails, and messages. Similarly, in cloud computing environments, a malicious customer could exploit the Downfall vulnerability to steal data and credentials from other customers who share the same cloud computer.
Data Exposure in Superscalar Computers
超标量计算机 Superscalar Computing
虚拟地址 Virtual address space
CPU 给每个进程提供虚拟地址空间以隔离每个进程占用的内存,程序访问内存的虚拟地址将被转换为页表条目(PTE)。如果虚拟地址超出了程序允许访问的地址区间,将会被阻止。
上下文切换 Context switching
CPU 会出现频繁的进程切换,在上下文切换时,必须切换虚拟地址空间和寄存器上下文,因此新进程将不能访问先前进程的存储器和寄存器。
多线程 Simultaneous multithreading
多线程(SMT)允许多个线程在同一个内核上同时执行,同时共享相同的硬件资源。
预测执行 Speculative execution
当一条指令依赖于先前未解析的操作时,CPU 会根据某种预测推测性地执行该指令。当预测不正确时,CPU 会刷新不正确的执行并重新执行它们以获得正确的结果。预测执行在架构上对软件是不可见的,但它的副作用可以被观察到。
数据化并行 Single instruction multiple data (SIMD)
SIMD (Single Instruction, Multiple Data)是一种数据级并行性技术,它允许处理器在同一时刻执行相同的操作,但是作用于不同的数据。
AVX2 和 AVX-512 是 x86 架构中的重要 SIMD 扩展,提供超宽向量寄存器方便大量并行数据计算。
高速缓存 Cache
如果数据不存在于高速缓存级中(高速缓存未命中),则从下一级高速缓存或DRAM中提取对应的高速缓存行。
临时缓冲区 Temporal buffers
L1 发生缓存未命中时,正常手续需要从 L2 或更低级存储器中找到对应数据并写入 L1,写入完毕后再从 L1 读取数据。而填充缓冲区允许 CPU 提前获取 缓存行的数据位,而不是等到整个缓存行被加载到 L1 缓存中,CPU 可以将这些数据位快速转发给依赖于这些数据的后续操作(即使整个缓存行还没有完全加载到 L1)。
类似地,当 CPU 执行写操作时,它需要将数据写入内存。如果写入的数据还没有立即提交到缓存中,CPU 会使用一个 存储缓冲区 来临时存储这些数据。
内存类型 Memory types
CPU 支持各种内存类型,以执行缓存策略:回写(WB)、直写(WT)、写保护(WP)、写组合(WC)、不可缓存(UC)。UC 和 WC都是不可缓存的。
UC 是 I/O 设备或特殊寄存器的内存地址,防止数据不一致,不写入 Cache
WC 是批量写回技术,由于数据量大且短时间不会再用到,不写入 Cache
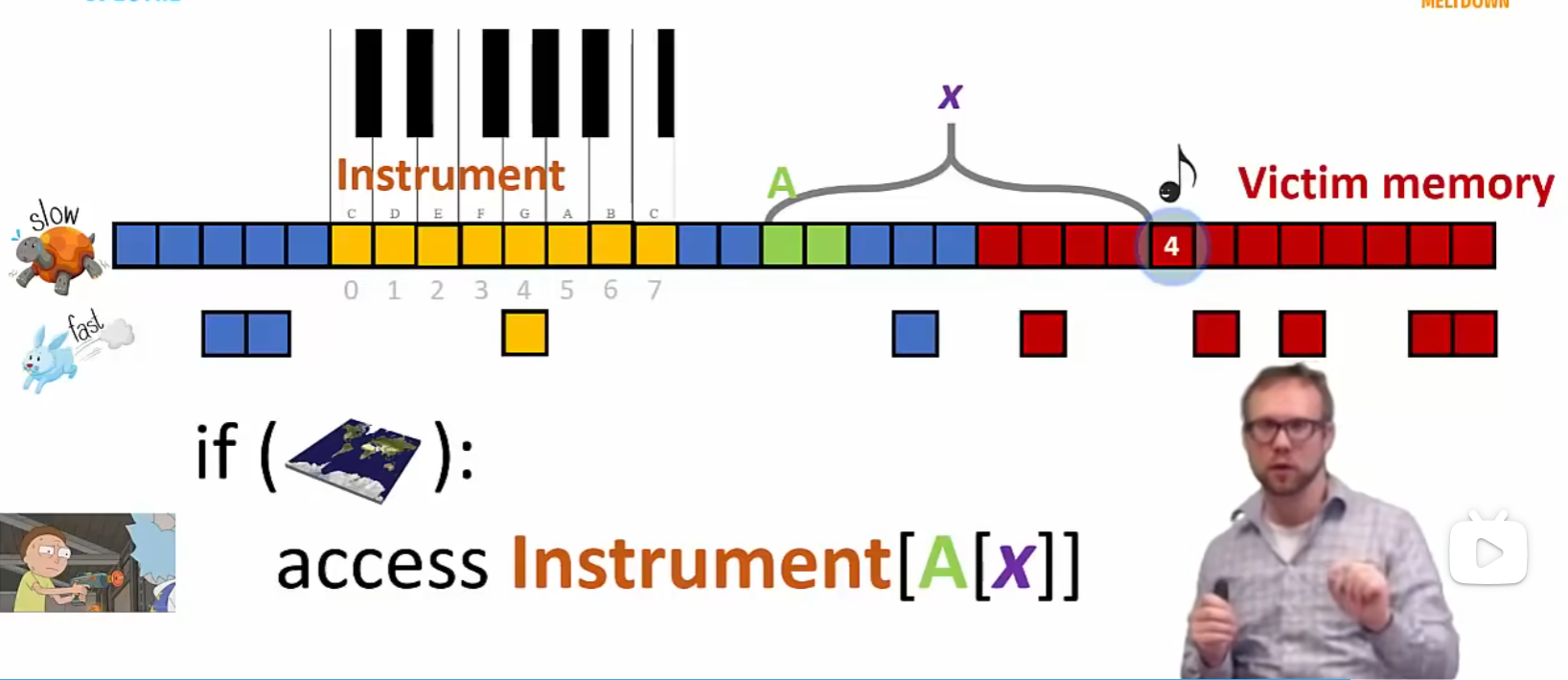
Gather Data Sampling
Gather Instruction
gather 指令可以高效访问非连续内存数据
访问的所有内存地址来源于 base 寄存器和 index 寄存器,根据 Mask 选取有效的内存数据,拼接到 Result 宽寄存器中
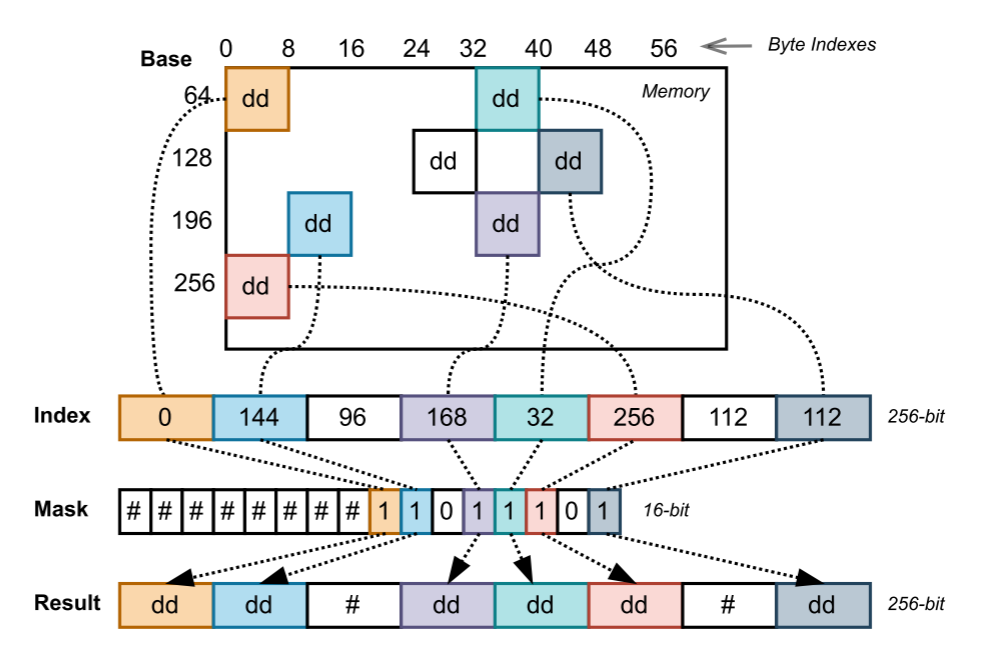
- 对于掩码为 0 的数据,不进行读取
- 读取后会在 cache 中存储一份,方便同一条 gather 指令中的重复读取
- 并行、推测地读取全部内存数据,它们必须同时成功或失败
- 开辟中间变量保存已经读取的部分,避免中断导致全部重新读取
当 gather 指令中间发生中断时,CPU 会利用临时 buffer 存储已经读取的数据(从 DRAM 或 cache 中保存),方便中断结束后 gather 指令直接从中间重新运行。当 gather 指令错误的结束时,CPU 将抛弃这些值。
gather 指令格式vpgatherdd displacement(base, index, scale), dst{mask}
displacement 是一个偏移量,base 是基址寄存器,index 是索引寄存器,scale 是倍数因子,dst 是写入寄存器,mask 是掩码寄存器。
Exploiting Gather Data Sampling
1 | |
Step (i): Increase the transient window
Transient window 是 CPU 内部进行的预测性操作的一段时间窗口。在这一段时间内,CPU会执行一些指令,假设这些指令的操作是正确的,即使在实际执行时,可能由于某些分支预测失败或数据依赖错误,这些操作的结果不会最终提交给程序。
在预测执行期间,CPU 执行的指令可能会影响系统状态(如缓存),而这些影响可能会被利用以获取未授权的数据,即使这些数据最终没有影响程序的最终结果。
1 | |
Step (ii): Gather uncacheable memory
1 | |
Step (iii): Encode (transient) data to cache
1 | |
Step (iv): Scan the cache
1 | |
Increase the transient window
1 | |
通过反复访问 cache 中不存在的内存地址数据来扩大 transient window,通过这种操作为 gather 指令的攻击准备好前期条件。