【论文】DRAWNAPART:A Device Identification Technique based on Remote GPU Fingerprinting
会议:NDSS 2022
论文链接:https://www.ndss-symposium.org/wp-content/uploads/2022-93-paper.pdf
论文分析
Introduction 逻辑链
(1) 研究是有意义的
浏览器追踪会给网站所有者带来巨大的经济效益,网站所有者有合理的动机去追踪用户
(2) 现有的浏览器追踪方法及其不足
- 传统的基于 Cookies 的追踪方法:被法规限制
- 浏览器指纹识别:通过 JS 脚本采集浏览器软硬件配置信息,将其组合成唯一设备标识符:
- 优点:精确度高,已广泛使用
- 缺点:浏览器指纹会不断演变,攻击者难以将指纹的演变串联成连贯链条(尤其是当存在硬件和软件配置完全相同的设备时)
(3) 本文所做的工作
尽管设备标称配置相同,但制造过程中的物理差异(如晶体管延迟、材料不均匀等)会导致硬件存在微小但可检测的差异。提出基于 GPU 执行单元速度差异的指纹技术 DRAWNAPART
核心问题:在硬件和软件配置完全相同的设备上,浏览器指纹跟踪是否可行?
(4) 本文工作遇到的挑战
- 浏览器环境中攻击者权限有限
- 无法控制运行时环境
- 接触系统的时间极短
(5) 本文工作的贡献
- 设计与实现:提出基于 GPU 执行单元速度差异的指纹技术 DRAWNAPART,捕捉 GPU 间微小差异
- 性能验证:通过多组相同设备实验,证明其能区分硬件和软件完全相同的设备
- 实际应用提升:通过大规模实验,展示其对现有指纹算法 (FP-STALKER) 跟踪精度的显著提升
- 防御建议:讨论可能的对抗措施及其优缺点
BackGround 逻辑链
解释本文核心的两个技术点:GPU EU 和 WebGL
GPU FringerPrinting 逻辑链
(1) 指纹设计的核心动机
- 对设备进行唯一性识别,专注于区分硬件和软件完全相同的设备
- 利用GPU中各个执行单元 (EU) 的统计性速度差异,来唯一标识整个系统
(2) 设计思路
渲染 -> 延迟 -> 轨迹生成
(3) 实现细节
渲染、延迟、轨迹生成的具体代码实现
(4) 结果速览
肉眼可以区分不同设备的指纹
论文精读
Abstract
Browser fingerprinting aims to identify users or their devices, through scripts that execute in the users’ browser and collect information on software or hardware characteristics. It is used to track users or as an additional means of identification to improve security. Fingerprinting techniques have one significant limitation: they are unable to track individual users for an extended duration. This happens because browser fingerprints evolve over time, and these evolutions ultimately cause a fingerprint to be confused with those from other devices sharing similar hardware and software. In this paper, we report on a new technique that can significantly extend the tracking time of fingerprint-based tracking methods. Our technique, which we call DRAWNAPART, is a new GPU fingerprinting technique that identifies a device from the unique properties of its GPU stack. Specifically, we show that variations in speed among the multiple execution units that comprise a GPU can serve as a reliable and robust device signature, which can be collected using unprivileged JavaScript. We investigate the accuracy of DRAWNAPART under two scenarios. In the first scenario, our controlled experiments confirm that the technique is effective in distinguishing devices with similar hardware and software configurations, even when they are considered identical by current state-of-the-art fingerprinting algorithms. In the second scenario, we integrate a one-shot learning version of our technique into a state-of-the-art browser fingerprint tracking algorithm. We verify our technique through a large-scale experiment involving data collected from over 2,500 crowd-sourced devices over a period of several months and show it provides a boost of up to 67% to the median tracking duration, compared to the state-of-the-art method. DRAWNAPART makes two contributions to the state of the art in browser fingerprinting. On the conceptual front, it is the first work that explores the manufacturing differences between *Both authors are considered co-first authors. identical GPUs and the first to exploit these differences in a privacy context. On the practical front, it demonstrates a robust technique for distinguishing between machines with identical hardware and software configurations, a technique that delivers practical accuracy gains in a realistic setting.
背景:浏览器指纹识别旨在通过执行用户浏览器中的脚本,收集软硬件特征信息来识别用户或其设备。它被用于跟踪用户或作为增强安全性的额外身份验证手段。
已有工作缺陷:无法长期跟踪个体用户 (浏览器指纹会随时间演变 => 导致同一设备的指纹与其他具有相似软硬件的设备指纹混淆)
本文工作:提出一种新技术 DRAWNAPART,可显著延长基于指纹的跟踪方法的跟踪时长。并证明 GPU 内部多个执行单元(Execution Units, EU)的速度差异可形成可靠且鲁棒的设备签名,且可通过无特权 JavaScript 脚本采集。
实验部分:
已有工作缺陷:无法长期跟踪个体用户 (浏览器指纹会随时间演变 => 导致同一设备的指纹与其他具有相似软硬件的设备指纹混淆)
本文工作:提出一种新技术 DRAWNAPART,可显著延长基于指纹的跟踪方法的跟踪时长。并证明 GPU 内部多个执行单元(Execution Units, EU)的速度差异可形成可靠且鲁棒的设备签名,且可通过无特权 JavaScript 脚本采集。
实验部分:
- 实验室控制实验:在硬件和软件配置相同的设备上,即使现有最先进的指纹识别算法认为这些设备“完全相同”,DRAWNAPART 仍能有效区分它们。
- 实际部署实验:将 DRAWNAPART 的单样本学习版本集成至当前最先进的浏览器指纹跟踪算法中,通过从 2500 多台众包设备采集的数月数据验证其有效性。
- 首次探索了相同型号 GPU 的制造差异,并首次将这种差异应用于隐私场景。
- 提出一种鲁棒技术,可区分软硬件配置完全相同的设备,并在实际环境中实现了显著的精度提升。
Introduction
Privacy is dignity. It is a human right. In the domain of web browsing, the right to privacy should prevent websites
from tracking user browsing activity without consent. This is the case in particular for cross-site tracking, in which
website owners collude to build browsing profiles spanning multiple websites over extended periods of time.
Unfortunately for users, the right to privacy conflicts with business interests. Website owners are highly interested in
tracking users for the purpose of showing them ads they are more likely to click on, or to recommend products they are
more likely to purchase. We focus on the common scenario where identifying a browser is equivalent to tracking a user.
The traditional way to track users is with cookies, small files that are stored by the browser at the request of the
website, and forwarded to the website on demand [50]. Recent regulations restrict and supervise the acquisition of
private data by websites [4, 31], and in particular require that users consent to the use of cookies. Furthermore, in an
effort to protect users’ privacy and curb tracking, modern browsers restrict cookie-based tracking, especially
third-party trackers that attempt to track users across multiple unrelated websites. To overcome the limitations of
cookies, less scrupulous websites often resort to an approach called browser fingerprinting. To fingerprint a browser,
the website provides a script that queries the browser’s software and hardware configuration to collect attributes, such
as the browser’s version, OS, timezone, screen, language, list of fonts, or even the way the browser renders text and
graphics. The diversity of configurations allows websites to discriminate devices and, hence, to track users, without
the use of cookies [52], even in a collection spanning millions of fingerprints [43]. Surveying the Internet Network and
Distributed Systems Security (NDSS) Symposium 2022 27 February - 3 March 2022, San Diego, CA, USA ISBN 1-891562-74-6
https://dx.doi.org/10.14722/ndss.2022.24093 www.ndss-symposium.org arXiv:2201.09956v1 [cs.CR] 24 Jan 2022 demonstrates
that browser fingerprinting techniques are prevalent and used by many websites, no matter their category or ranking [38,
40, 59].
为什么有浏览器追踪技术:网站所有者出于经济利益。
传统追踪方式 (Cookies):通过网站请求浏览器存储一些小文件并传回服务器。近年来法规严格限制数据采集并阻断第三方 Cookies。
浏览器指纹识别 (替换方案):通过 JS 脚本采集浏览器软硬件配置信息 (如版本、操作系统、时区、屏幕分辨率、语言、字体列表、图形渲染方式等),利用这些属性的组合差异生成唯一设备标识符。精确度高,已广泛使用。
传统追踪方式 (Cookies):通过网站请求浏览器存储一些小文件并传回服务器。近年来法规严格限制数据采集并阻断第三方 Cookies。
浏览器指纹识别 (替换方案):通过 JS 脚本采集浏览器软硬件配置信息 (如版本、操作系统、时区、屏幕分辨率、语言、字体列表、图形渲染方式等),利用这些属性的组合差异生成唯一设备标识符。精确度高,已广泛使用。
A significant difficulty of fingerprint-based tracking is that browser fingerprints evolve. As shown by Vastel et al.
[73], fingerprints change frequently, sometimes multiple times per day, due to software updates and configuration
changes. To track a user, an adversary must link fingerprint evolutions into a single coherent chain. This process is
made difficult by the existence of devices with identical hardware and software configurations. It is difficult for an
adversary to correctly link a fingerprint if there is a set of identical devices to which it might belong. This limits
the adversary’s tracking duration. In Vastel et al.’s evaluation over a dataset of nearly 100,000 fingerprints collected
from 1,905 distinct browser instances, with a wide variety of fingerprinting attributes, their stateof-the-art machine
learning technique was able to deliver a median tracking time of less than two months. In this work, we bring a new
insight to the challenge of browser fingerprinting identical computers, by observing that even nominally identical
hardware devices have slight differences induced by their manufacturing process. These manufacturing variations are
shown to enable the extraction of unique and robust fingerprints from a variety of devices, both large and small, in
other settings [44, 71]. If an adversary were able to extract such a hardware fingerprint from the user’s device, it
would significantly extend the adversary’s ability to track them. Extracting a hardware fingerprint from a browser,
however, is far from trivial—since the attacker has little control. In particular, the attacker can only interact with
the system through unprivileged JavaScript code and WebGL graphics primitives—the attacker has no control over the
runtime environment of the system, including background processes and simultaneous user activity—and the attacker has
very limited exposure to the system, making classical machine learning pipelines that rely on long training phases all
but useless. Thus, in this paper we raise the following question: Can browser fingerprinting work on devices with
identical hardware and software configurations?
浏览器指纹识别的不足:浏览器指纹会不断演变。攻击者若想持续跟踪用户,必须将指纹的演变串联成连贯链条,但当存在硬件和软件配置完全相同的设备时,这一过程会变得极其困难——攻击者难以判断某个指纹究竟属于目标设备还是其他相同配置的设备,这严重限制了跟踪的持续时间。现有最先进的机器学习技术在近 10 万个指纹数据集上评估的中位数跟踪时间不足两个月。
本文提出了一种突破性思路:尽管设备标称配置相同,但制造过程中的物理差异(如晶体管延迟、材料不均匀等)会导致硬件存在微小但可检测的差异。
挑战:浏览器环境中攻击者权限有限,无法控制运行时环境,且接触系统的时间极短
核心问题:在硬件和软件配置完全相同的设备上,浏览器指纹跟踪是否可行?
本文提出了一种突破性思路:尽管设备标称配置相同,但制造过程中的物理差异(如晶体管延迟、材料不均匀等)会导致硬件存在微小但可检测的差异。
挑战:浏览器环境中攻击者权限有限,无法控制运行时环境,且接触系统的时间极短
核心问题:在硬件和软件配置完全相同的设备上,浏览器指纹跟踪是否可行?
Our Contribution. We claim this is possible, and we assess this claim with DRAWNAPART, a technique that measures small
differences among the Execution Units (EUs) that make up a modern Graphics Processing Unit (GPU). By fingerprinting the
GPU stack, DRAWNAPART can tell apart devices with nominally identical configurations, both in the lab and in the wild.
In a nutshell, to create a fingerprint, DRAWNAPART generates a sequence of rendering tasks, each targeting different
EUs. It times each rendering task, creating a fingerprint trace. This trace is transformed by a deep learning network
into an embedding vector that describes it succinctly and points the adversary towards the specific device that
generated it. We evaluate DRAWNAPART in two main scenarios. First, to validate the method’s ability to distinguish
nominally identical configurations, we perform a series of controlled experiments under lab conditions. We experiment
with multiple sets of identical devices from vendors including Intel, Apple, Nvidia and Samsung, and demonstrate that
DRAWNAPART consistently improves identification of these nominally identical devices, achieving high identification
accuracy in multiple hardware configurations, even though state-of-the-art browserbased fingerprinting methods cannot
tell them apart. Second, to show that DRAWNAPART affects user privacy, we integrate the technique into Vastel et al.’s
state-of-the-art fingerprinting algorithm from IEEE S&P 2018 [73], which uses machine learning to link browser
fingerprint evolutions. We show that the median tracking duration is improved by up to 66.66% once we add the DRAWNAPART
fingerprint. In summary, this paper makes the following contributions: • We design and implement DRAWNAPART1, a GPU
fingerprinting technique based on the relative speed of EUs, that observes minute differences between GPUs (Section
III). • We investigate the performance of our fingerprinting technique with multiple sets of identical devices,
demonstrating that it can tell apart devices with identical hardware and software configurations (Section V). • We
integrate DRAWNAPART into Vastel et al.’s fingerprinting algorithm and show, through a large-scale crowdsourced
experiment with over 2,500 unique devices and almost 371,000 fingerprints, that DRAWNAPART delivers considerable gains
to the tracking accuracy of this stateof-the-art approach (Section VI). • We suggest possible countermeasures against
our fingerprinting technique, and discuss their advantages and drawbacks (Section VII-B).
论文的贡献:
- 设计与实现:提出基于GPU执行单元速度差异的指纹技术DRAWNAPART,捕捉GPU间微小差异(第III节)。
- 性能验证:通过多组相同设备实验,证明其能区分硬件和软件完全相同的设备(第V节)。
- 实际应用提升:通过大规模实验,展示其对现有指纹算法(FP-STALKER)跟踪精度的显著提升(第VI节)。
- 防御建议:讨论可能的对抗措施及其优缺点(第VII-B节)。
BackGround
Browser Fingerprinting
Mowery et al. [56] discuss fingerprinting on the Web. As they state, fingerprinting can be applied constructively or
destructively. An example of constructive use of fingerprints would be to identify fraudulent users trying to log in
while masquerading as legitimate users. Browser fingerprinting can be used to detect bots [27, 48, 74], or support
authentication, where the fingerprint is used in addition to a traditional authentication mechanism [20, 51]. A
destructive use might involve tracking users without consent [17, 40]. In this scenario, fingerprinting is used to
augment or replace cookies—e.g., to track across multiple domains, or when users disable or delete cookies. Our
technique can be applied to either scenario. Many fingerprinting techniques exist in the wild [24, 39, 57, 58]. They
rely heavily on differences in devices’ hardware and software characteristics found in HTTP header fields and JavaScript
attributes. The key challenge is to identify features and attributes that further discriminate devices and allow for
their unique identification, and to overcome the tendency of these features to evolve over time because of changes to
the user’s software, configuration, or environment.
指纹识别技术的两种利用场景:建设性 + 破坏性,DRAWNAPART 均可适用
当前的指纹识别技术主要依赖于 HTTP 请求头和 JavaScript 属性中反映的设备和软件特征差异。
核心挑战:既要找到能有效区分设备的特征,又要克服这些特征因软件更新、配置变更或环境变化而产生的动态演化问题。
当前的指纹识别技术主要依赖于 HTTP 请求头和 JavaScript 属性中反映的设备和软件特征差异。
核心挑战:既要找到能有效区分设备的特征,又要克服这些特征因软件更新、配置变更或环境变化而产生的动态演化问题。
GPU Programming
The Graphics Processing Unit (GPU) is specialized hardware for rendering graphics. GPUs have highly parallel
architectures that are composed of multiple Execution Units (EUs), or shader cores, which can independently perform
arithmetic and logic operations. Most consumer desktop and mobile processors from the past decade have on-chip GPUs with
multiple EUs. For example, the UHD Graphics 630 GPU—integrated into Intel Core i5-8500 CPUs—includes 24 EUs, while the
Mali-G72 GPU—integrated into the Samsung Exynos 9810 chipset used in Galaxy S9, S9+, Note9, and Note10 Lite
devices—includes 18 EUs. Web Graphics Library (WebGL) is a cross-platform API for rendering 3D graphics in the browser
[12]. WebGL is implemented in major browsers including Safari, Chrome, Edge, and Firefox. Derived from native OpenGL ES
2.0, a library designed for developing graphic applications in C++, WebGL implements a JavaScript API for rendering
graphics in an HTML5 canvas element. WebGL takes a representation of 3D objects as a list of vertices in space and
information on how to render them, and translates them into a two-dimensional raster image that can be displayed on
screen. WebGL abstracts this process as a pipeline. Two pipeline steps which are of interest to this work are the vertex
shader, which places the vertices in the two-dimensional canvas, and the fragment shader, which determines the color and
other properties of each fragment. The vertex and fragment shaders can run user-supplied programs, written in a
C-derived programming language named GL Shading Language (GLSL).
- GPU 有很多执行单元 EU (SM)
- WebGL 是一种跨浏览器 3D 图形渲染 API
GPU FringerPrinting
Motivation
Similar to past work [39, 52], we aim to uniquely identify devices. However, unlike previous work, which rely on the
diversity of hardware and software configurations, we focus on distinguishing identical devices. As we show
experimentally, this additional distinguishing power can considerably enhance the tracking capabilities of existing
fingerprinting methods. To do so, we incorporate techniques similar to the arbiterbased Physically Unclonable Function
(PUF) concept of Lee et al. [53]. In an arbiter PUF, the statistical delay variations of wires and transistors across
multiple instances of the same integrated circuit design are used to uniquely identify individual instances of the
integrated circuit. In our case, we harness the statistical speed variations of individual EUs in the GPU to uniquely
identify a complete system.
目标:对设备进行唯一性识别,专注于区分硬件和软件完全相同的设备。
利用GPU中各个执行单元(EU)的统计性速度差异,来唯一标识整个系统。
利用GPU中各个执行单元(EU)的统计性速度差异,来唯一标识整个系统。
Design
With unfettered access to the GPU, an adversary could measure the speed of each EU and use those measurements as a
fingerprint. However, websites only have limited access to the GPU through the JavaScript and WebGL APIs. WebGL provides
a high-level abstraction that makes it a challenge to target specific EUs and to time computations accurately. We
overcome this challenge by using short GLSL programs executed by the GPU as part of the vertex shader (cf. Section
II-B). We rely on the mostly predictable job allocation in the WebGL software stack to target specific EUs. We observe
that, when allocating a parallel set of vertex shader tasks, the WebGL stack tends to assign the tasks to different EUs
in a non-randomized fashion. This allows us to issue multiple commands that target the same EUs. Finally, instead of
measuring specific tasks, we ensure that the execution time of the targeted EU dominates the execution time of the whole pipeline. We do so by assigning the non-targeted EUs a
vertex shading program that is quick to complete, while assigning the targeted EUs tasks whose execution time is highly
sensitive to the differences among individual EUs. As shown in Figure 1, our fingerprint is created by executing a
sequence of drawing operations. We measure the time to draw a sequence of points with carefully chosen shader programs.
The technique consists of three main steps:
Render. We instruct the WebGL API to draw a number of points in parallel. Points are the simplest object that WebGL can
draw, and each consists of only a single vertex. Using points minimizes the noise from the pipeline and its interference
with our technique. The position of each point is determined by an attacker-controlled vertex shader. Stall. For most
points, the attacker-controlled vertex shader returns a hard-coded value. For a specific subset of the points the shader
applies a function, which we call a stall function, to compute the point’s position. The manner in which the entire
graphics stack distributes the points to be drawn to the EUs allows us to influence which EU is chosen to run the stall
function. It takes much longer to compute the position with the stall function than the hard-coded value. As a result,
the time needed to render the entire set of points corresponds to the time taken by the EUs running the stall function.
Trace Generation. We execute the drawing command several times, each time selecting a different vertex to stall. For
each execution, we store the time taken. The fingerprint output by our technique is therefore a vector, named a trace,
which contains the sequence of timing measurements. We note that prior browser fingerprinting techniques extract
deterministic fingerprints, which remain identical as long as the device’s software and configuration have not changed.
Our technique, in contrast, is based on timing measurements and, as such, is non-deterministic—multiple measurements
made on the same device will return different values due to the effects of measurement noise, quantization, and the
impact of other tasks running at the same time.
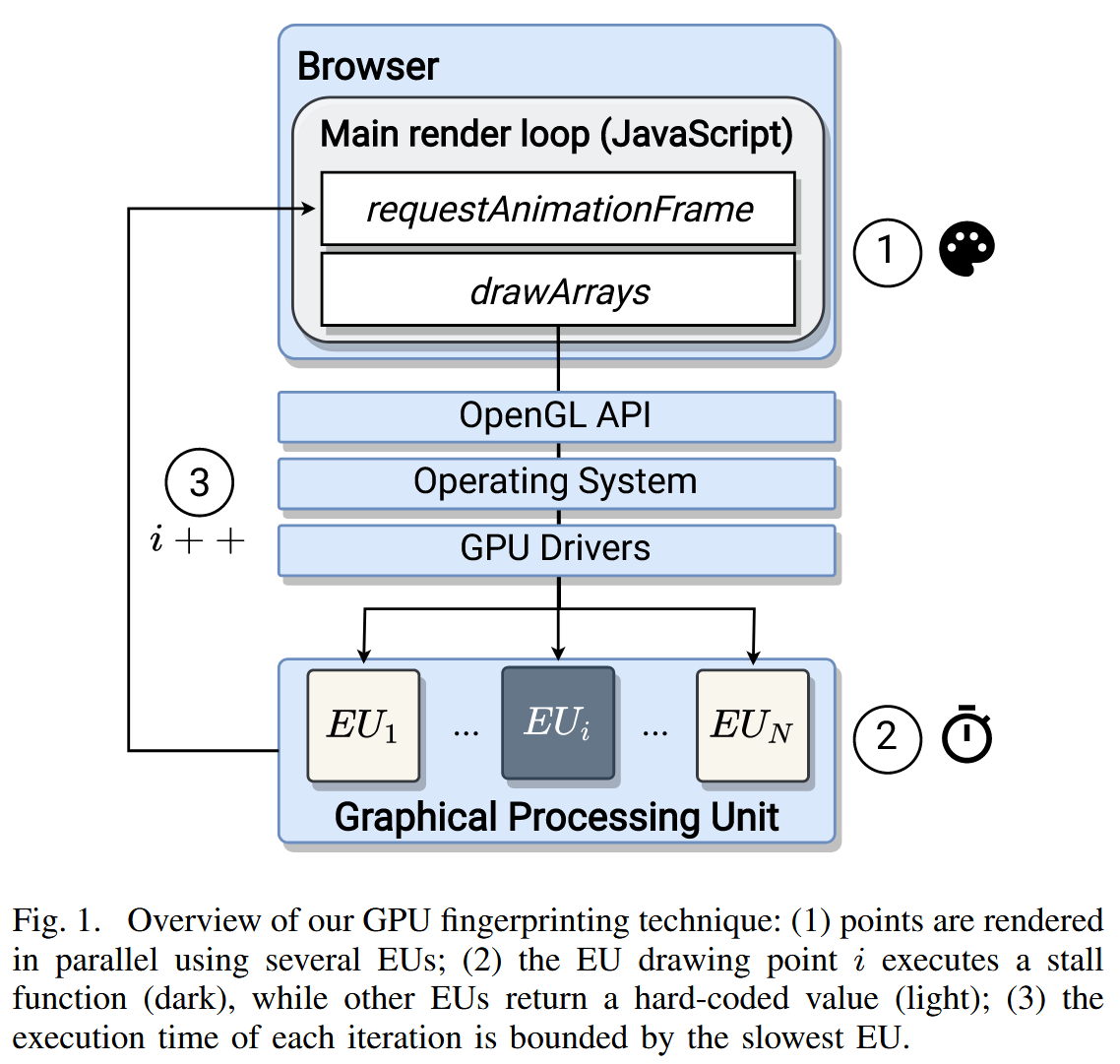
在无限制访问 GPU 的情况下,攻击者可以直接测量每个执行单元的速度并将其作为指纹。然而,网站只能通过 JavaScript 和 WebGL API 对 GPU 进行有限访问。WebGL 的高层抽象特性使得针对特定 EU 和精确计时变得困难。我们通过以下方法克服了这一挑战:
在顶点着色器中执行简短的 GLSL 程序,利用 WebGL 软件栈中可预测的任务分配机制来定位特定 EU。我们观察到,当分配一组并行的顶点着色器任务时,WebGL 栈倾向于以非随机化的方式将任务分配给不同的 EU。这使得我们可以通过多次命令重复定位相同的 EU。
我们并不直接测量具体任务,而是确保目标 EU 的执行时间主导整个渲染管道的耗时。具体方法是为非目标 EU 分配快速完成的顶点着色程序,而为目标 EU 分配对个体差异高度敏感的任务(例如计算密集型函数)。如图 1 所示,我们的指纹生成技术通过执行一系列绘制操作实现。我们测量绘制一组精心设计着色器程序顶点的时间,具体步骤如下:
在顶点着色器中执行简短的 GLSL 程序,利用 WebGL 软件栈中可预测的任务分配机制来定位特定 EU。我们观察到,当分配一组并行的顶点着色器任务时,WebGL 栈倾向于以非随机化的方式将任务分配给不同的 EU。这使得我们可以通过多次命令重复定位相同的 EU。
我们并不直接测量具体任务,而是确保目标 EU 的执行时间主导整个渲染管道的耗时。具体方法是为非目标 EU 分配快速完成的顶点着色程序,而为目标 EU 分配对个体差异高度敏感的任务(例如计算密集型函数)。如图 1 所示,我们的指纹生成技术通过执行一系列绘制操作实现。我们测量绘制一组精心设计着色器程序顶点的时间,具体步骤如下:
- 渲染:通过 WebGL API 并行绘制多个点。点的绘制能最小化渲染管道中的噪声干扰。每个点的位置由攻击者控制的顶点着色器决定。
- 延迟:对于大多数点,顶点着色器返回固定值;对于特定子集的点,着色器调用延迟函数计算其位置。通过 WebGL 栈分配任务的规律,我们能够控制哪些 EU 执行延迟函数。由于延迟函数的计算时间远长于固定值,渲染整组点的总时间取决于执行延迟函数的 EU 耗时。
- 跟踪生成:多次执行绘制命令,每次选择不同的顶点施加延迟,记录每次执行时间。最终生成的指纹是一个时序向量,包含一系列时间测量值。与传统的确定性指纹技术不同(依赖设备软硬件的静态属性),DRAWNAPART 基于时序测量,因此具有非确定性。同一设备的多次测量会因噪声、量化误差和并发任务影响而产生差异,但通过机器学习仍可提取稳定特征。
Implementation
We now describe the implementation of each design step. Render. The WebGL API exposes the drawArrays() function, which
allows dispatching multiple drawing operations in parallel to the GPU. We invoke drawArrays() several times, each time
rendering multiple points in parallel. Listing 1 describes our main render loop. We execute the rendering process by
calling drawArrays (line 5). For each iteration, we save the time to execute drawArrays into the trace array. We
evaluated several ways of measuring the rendering time, as explained further in Section V-A. Briefly put, the onscreen
measurement method executes a relatively small number of computationally intensive operations, while the offscreen and
GPU measurement methods execute a larger number of less computationally intensive operations. The full source code for
these settings can be found in our artifact repository, as listed in Section IX. After point_count iterations, the code
sends the trace array to our back-end server (line 15), and terminates the loop.
Stall. In the current implementation of WebGL, a single call to drawArrays() generates multiple drawing operations in
the underlying graphics API, which appear to assign vertices to EUs in a deterministic order during vertex processing.
The operations are differentiated by a global variable, named gl_VertexID. This special variable is an integer index for
the current vertex, intrinsically generated by the hardware in all of the graphics APIs used to implement WebGL as it
executes gl.drawArrays. We created a vertex shader in GLSL that examines the gl_VertexID identifier, and executes a
computationally intensive stall function only if it matches an input variable named shader_stalled_point_id provided by
the JavaScript code running on the CPU. Listing 2 describes the vertex shader code. In the onscreen setting, the vertex
shader checks if shader_stalled_point_id equals gl_VertexID. In the offscreen and GPU settings, the vertex shader treats
shader_stalled_point_id as a bit mask and checks if bit 1 << gl_VertexID is set. In both cases, if the point is selected the vertex shader
program executes the stall function (line 5). Otherwise, the shader exits quickly. Trace Generation. By executing this parallel drawing
operation multiple times, each with a different value for shader_stalled_point_id, we iterate over the different EUs
and measure the relative performance of each. The output is a trace of multiple timing measurements, corresponding
to the time taken by the targeted EU to draw the scene.
具体实现机制不再赘述:渲染 -> 延迟 -> 轨迹生成
Raw Traces
Before evaluating DRAWNAPART, we tested whether we can visually distinguish devices. Figure 2 shows traces collected
from two GEN 3 devices. We collect 50 traces from each device, each trace consisting of 176 measurements of 16 points.
The measurements are divided into 16 groups of 11, where in each group we stall a different point. The color of a point
indicates the rendering time, ranging from virtually 0 (white) to 90 ms (blue). Red vertical bars indicate group
boundaries. As we can see, the rendering time in the first half of the traces is significantly faster than in the second
half. Moreover, while there are some timing variations in the traces of the same device, the traces display patterns
that are distinct between devices, allowing us to distinguish them.
在正式评估 DRAWNAPART 之前,我们首先测试了能否通过视觉方式区分设备。图 2 展示了两台 GEN3 设备的时序轨迹对比。我们从每台设备收集了 50 条轨迹,每条轨迹包含对 16 个点的176 次时间测量。这些测量被分为 16 组 (每组 11 次),每组针对不同的延迟点。图中通过颜色编码表示渲染时间,从接近 0 毫秒 (白色) 到 90 毫秒 (蓝色) 渐变,红色竖线表示组间边界。
不同设备的轨迹可以通过视觉区分。
不同设备的轨迹可以通过视觉区分。
【论文】DRAWNAPART:A Device Identification Technique based on Remote GPU Fingerprinting
https://dmx20070206.github.io/2025/04/28/【论文】DRAWNAPART:A Device Identification Technique based on Remote GPU Fingerprinting/